Что такое FTS
Предисловие
Что такое FTS
FTS - это технология создания информационных систем предприятия. Разработана одним человеком (не считая пользователей и тестеров). Первая строка программного кода написана 27 ноября 2002 года. Версии продукта меняются каждый день.
По мнению экспертов, цена корпоративной информационной системы фактически не опускается ниже 5 млн. долларов. Данный продукт позволяет построить корпоративную информационную систему за 100 долларов.
Для кого предназначена эта книга
Книга предназначена для студентов, изучающих новые информационные технологии.
Об авторе
Родился в Одессе в 1957 году. Программист с 1971 года. Окончил факультет Вычислительной Математики и Кибернетики МГУ им. Ломоносова в 1978 году.12 лет работы в Москве (1978-1992), 7 лет работы в Израиле (1992-1999), 2 года работы в США (2000-2001), последние годы (с конца 2001 года) живет и работает в Петрозаводске (Россия, Карелия).
Терминология
КИС = корпоративная информационная система. По смыслу включает такие понятия как ERP (enterprise resource planning), CRM (customer requirements management), Logistics и другие типовые системы для решения определенных задач
Клиент-сервер = способ построения КИС («архитектура»), при котором вся информация хранится и обрабатывается на одной машине («сервер»), а на других машинах только отображается по их требованию («клиенты»), с них вводится и обновляется.
WEB-технологии – технологии создания веб-сайтов, в том числе динамических.
HTML – язык создания статических сайтов
JAVA – язык программирования.
JSP – веб-технология, основанная на JAVA и HTML
Open Source – программные продукты выставленные в Интернет для использования по бесплатной (или условно-бесплатной) лицензии
Общие соображения
Продукт одного программиста
Есть мнение, что хороший программный продукт может быть создан только в большом коллективе. Это мнение ложно. Покажем это.
Качество продукта измеряется количеством версий от замысла до сего дня. Если автор один, смена версии длится минуты. Если авторов несколько, смена версии длится дни, месяцы, годы. Соответственно количество версий за то же время у одного автора на два-три-четыре порядка больше, качество продукта на два, три, четыре порядка лучше. Все это верно только при условии, что у автора есть прямая связь с потребителем (а для этого нужны еще люди, организующие такую связь)
Уровни определенности
Я буду различать
1. Требования к системе (Т)
2. Правила, которые однозначно вытекают из этих требований (П)
3. Дополнительные правила разной степени очевидности, (вместе с обязательными правилами) определяющие модель данных (М)
4. Особенности данной (пока единственной) реализации данной модели (Р)
Буквы Т, П, М, Р (в скобках) как правило будут указывать уровень определенности утверждений, как определено выше.
Постановка задачи
Создать такой инструментарий (Т), чтобы его могла использовать даже очень маленькая компания – клиент. КИС должна иметь очень малую стоимость и очень короткие сроки создания. Кроме того, должно быть обеспечено высокое качество информации. Кроме того, проблема расширения системы и проблема интеграции задач должны решаться в этой системе легко и просто.
Выбор пути
У большинства сегодня есть персональный компьютер, на котором стоит Windows и Internet Explorer. Большинство сегодня подключено к локальной сети предприятия, а многие даже к сети Интернет. Поэтому инструментарий должен строиться на основе веб-технологий.
Если внутри инструментария использовать платные продукты, то
клиенту придется за них платить. Поэтому надо использовать продукты серии Open Source
Выбор JAVA-JSP и отказ от SOA основан на тонких эстетических соображениях, которые я не буду здесь излагать.
Модель данных
При создании КИС проектирование и программирование должны быть разделены. Где проходит граница между ними, зависит от выбранной модели данных. Обычно граница проходит так, что проектирование и программирование требуют одинаковой трудоемкости
Модель данных, описанная ниже, проводит границу в пользу проектирования. Программирование оттесняется «на обочину» и локализуется. При этом проектирование сразу осуществляется на живой системе, без остановки ее работы.
Качество
В этой главе (для начинающих) мы будем исходить из общих представлений о качестве информации.
Качество и ответственность
Качество информации можно обеспечить только одним способом: за каждый смысловой сегмент информации должен отвечать конкретный человек.
Здесь неявно содержатся еще несколько предположений:
- Вся информация разбита на смысловые сегменты (блоки). Я называю эти блоки «объектами». С точки зрения системы все объекты одинаково (в некотором смысле).
- Все пользователи системы, которым дано право что-либо менять, должны быть известны системе поименно. Эта информация тоже есть смысловой сегмент, то есть «объект»
- Если человек не вышел на работу, ответственность за его объекты должна автоматически передаваться другому человеку. По смыслу это должен быть его непосредственный начальник. Таким образом, иерархия управленцев на производстве должна быть известна системе
- Даже если все пользователи заболели и не вышли на работу, кто-то должен взять на себя ответственность
Дерево объектов
Простейшей реализацией этих правил является следующая система предположений. (М)
- Все объекты связаны в одно дерево объектов.
- Когда пользователь входит в систему, он называет себя. Соответственно система позиционирует его в дереве. С этого момента все объекты, лежащие в дереве ниже его ему видны. Более того, у него есть полное право изменять эти объекты и даже удалять их. Это его «зона ответственности»
- Корню дерева объектов соответствует особый пользователь, который «отвечает за все и никогда не болеет». Я называю его «администратор пространства»
Данные, функции, операции
Объект можно рассматривать как контейнер, в котором лежат «элементы данных». Например, объекты, соответствующие пользователям, обязательно содержат имя пользователя и пароль (М). Он может содержать еще элементы данных, например «приветствие» (Р). Что такое элемент данных? Это пара «имя переменной – ее значение». Например, Имя пользователя может быть XUSER::CODE, а значение – ИВАНОВ (Р)
Кроме элементов данных у объектов есть функции. Например (Р) объекты могут уметь выбирать из своего поддерева все объекты, измененные за последние Х дней, где Х – параметр, заданный непосредственно перед запуском функции.
Функции следует отличать от операций. Например, «удалить объект» – это операция, а не функция.
Внутренние имена переменных, например, XUSER::CODE, следует отличать от внешних имен, например, «имя пользователя» (Р). На внутренние имена накладываются ограничения гораздо более жесткие, чем на имена внешние.
Тип объекта
Прежде чем работать с конкретным объектом, пользователь хотел бы иметь о нем предварительную информацию. Например, знать, какие именно элементы данных в этом объекте хранятся. Для этого мы вводим «тип объекта» (М)
Тип объекта определяет
- Список элементов данных (М)
- Список функций, применимых к объектам данного типа (М)
- Икону, используемую при отображении данного объекта в дереве объектов (Р)
Теперь, глядя на икону объекта в дереве, пользователь представляет себе, какие элементы данных в нем хранятся и какие именно функции на этом объекте выполнимы
Тип FTS аналогичен с одной стороны типу файла в Windows/UNIX (определен расширением имени файла). С другой он аналогичен классам C++/Java
(М) Ниже мы увидим, что типы соединены в дерево и даже в два дерева (с общим набором узлов). При определенных обстоятельствах эти деревья превращаются в ациклические графы.
Элементы данных
(Р) Некоторые элементы данных это переменные. Другие элементы данных это файлы. Формат переменной и тип файла закреплены за элементом данных навсегда.
Номер объекта
(Р) Когда система создает объект, она присваивает ему уникальный номер (ID). Все эти номера неотрицательные целые числа. Номер 0 соответствует корню дерева объектов («администратору пространства»).
Ключи
Некоторые элементы данных (некоторые поля) указывают на другие объекты системы. Это «ключи».
Поскольку ключ всегда указывает на объект определенного типа, то в интерфейсе легко устроить выпадающий список допустимых значений ключа. Однако тут есть несколько проблем (Р) Покажем эти проблемы и наши способы их решения
Как именно указывать на объект? Можно использовать номер объекта
Что делать, если значение не определено? В этом случае, номер объекта – нулевой (нулевой номер – корень дерева объектов). Значение NULL мы здесь не используем
Что делать, если допустимых значений слишком много?
Можно использовать другие интерфейс - элементы (кроме выпадающего списка)
- Отдельное окно с вариантами
- Ввод номера
Какой вариант (из трех) когда использовать?
(Р) Введем два порога (целые числа, например, 10 и 100).
До первого порога работает «выпадающий список»
После первого порога, но до второго, работает «отдельное окно»
После второго порога работает «ввод номера»
Пороги задает администратор пространства
Основные операции
Для того, чтобы деревья могли «жить», необходимо разрешить на них следующие операции (разрешены в зоне ответственности)
- Создать новый узел
- Удалить узел
- Передвинуть узел
- Изменить узел
Реальные ситуации
В этой главе (для продолжающих) мы примем во внимание те реальные ситуации, которые возникают в реальном использовании КИС.
Область видимости
Предположим, что сотрудники А и Б делят между собой всю работу подразделения. Ни один из них не является начальником другого. Это означает, что их зоны ответственности не пересекаются. Однако вполне возможна ситуация, когда сотруднику А надо видеть (хотя бы частично), что делает сотрудник Б, чтобы оптимизировать свою собственную работу. Иначе говоря, «зона видимости» сотрудника А должна быть шире чем «зона ответственности» сотрудника А. Это достигается следующим образом
Ярлыки
Разрешим в дереве объектов создавать не только новые объекты, но и ярлыки на объекты уже существующие. Для тех, кто знает Windows или UNIX, скажу, что в этих системах ярлык (shortcut) выводит пользователя прямо на объект и далее позволяет этот объект изменять. В FTS ярлык позволяет видеть объект и все поддерево лежащее под этим объектом, но не позволяет ничего изменять в этом поддереве. Таким образом, ярлык позволяет расширить область видимости, но не область ответственности.
С формально-математической точки зрения, ярлыки превращают дерево в ациклический граф с той только разницей, что первое ребро входящее в узел – особое.
Псевдоузлы
Узлы видимые под ярлыком называются «псевдоузлами». Псевдоузлы (в отличие от ярлыков) нельзя удалить: они возникают и исчезают только вместе с ярлыком, в поддереве которого они видны.
Переменный тип объекта
Реальный объект живет в системе долго. Поэтому у вас вполне может появиться желание изменить его тип. В FTS это возможно.
Для сравнения: в Windows вы можете поменять расширение файла. В этом случае ответственность за то, что новый вьюер сможет этот файл открыть, лежит на вас. В языках программирования (Java, C++) изменить тип существующего объекта невозможно.
Наследование
(М) Представим себе тип «человек». Введем в систему объект этого типа. Через некоторое время может случиться, что этот человек стал сотрудником предприятия. Логично ввести тип «сотрудник» и преобразовать объект к этому типу.
Известно, что всякий «сотрудник» является «человеком». Для нас это означает. Что список элементов данных типа «сотрудник» начинается со списка элемента данных типа «человек». Аналогично список функций типа «сотрудник» начинается со списка функций типа «человек».
Такое соотношение типов в FTS называется «наследованием»
Легко доказать, что отношение наследования связывает все типы в дерево («дерево наследования»).
(Р) По аналогии с языком Java
корень дерева наследования называется OBJECT
Корень дерева объектов (Р) имеет тип OBJECT. Условлено (Р), что никакой другой объект в системе не имеет этого типа.
Номер типа
(Р) Все типы имеют уникальные номера (ID) – неотрицательные целые числа. Тип OBJECT имеет номер 0.
Внешнее и внутреннее имя типа
Следует различать внутреннее имя типа (например, OBJECT) и внешнее имя типа (например, Объект).
(Р) Внешнее имя можно менять, внутреннее - нет. На внутреннее имя накладываются гораздо более строгие ограничения
Абстрактный тип
(М) Некоторым типам нельзя иметь объекты. По аналогии с Java, назовем такие типы «абстрактными».
Для чего нужны такие типы?
Во-первых, если тип А научить выполнять некоторую функцию, то достаточно унаследовать от этого типа другой тип Б, чтобы тип Б получил эту функцию «в наследство».
Во вторых, абстрактные типы удобны для «собирания» типов вместе в дереве наследования. Без этой возможности растущее дерево наследования очень неудобно просматривать.
Множественное наследование
В языке C++ есть «множественное наследование». В языке Java такого понятия нет.
Множественное наследование разрешает наследовать один тип (класс) сразу от нескольких типов (классов)
Если тип А умеет выполнять первую функцию, а тип Б вторую, то мы можем научить тип В обеим функциям, если унаследуем его и от А и от Б.
Списки элементов данных при таком множественном наследовании приписываются друг за другом, однако начала списков на совпадающем участке включаются только один раз. В этом отличие от С++, где начала списков включаются независимо от совпадения, что приводит к проблемам. Порядок приписывания совпадает с порядком определения.
Ярлыки в дереве наследования
Множественное наследование уже не может быть описано деревом, а только ациклическим графом. Но механизм превращения дерева в ациклический граф уже известен: ярлыки.
Тип-множество
(М) Предположим, что фирма Х набирает сотрудников, умеющих водить автомобиль и самолет. Предположим, что она заранее накапливает список кандидатов. Тогда тип «кандидат» должен быть унаследован от типа «водитель машины» и от типа «водитель самолета».
Однако возможен и другой случай. Сотрудникам фирмы А приходится иногда водить автомобиль, иногда самолет. Но «быть сотрудником» не обязательно влечет за собой «уметь водить автомобиль» или «уметь водить самолет». Однако водители обоих типов интересны только в том случае, если они – сотрудники. В этом случае стоит унаследовать типы «водитель машины» и «водитель самолета» от типа «сотрудник». Однако этого мало.
Предположим, человек Ч поступил на работу как сотрудник, но в момент поступления он не умел водить ни самолет, ни автомобиль. В какой то момент времени человек может стать «водителем автомобиля». В другой момент он может стать «водителем самолета». Затем он может утратить то и/или другое право, например, по истечению срока действия лицензии. Как описать это в нашей модели данных?
Пусть дерево наследование содержит четыре типа (объект, сотрудник, водитель машины, водитель самолета).
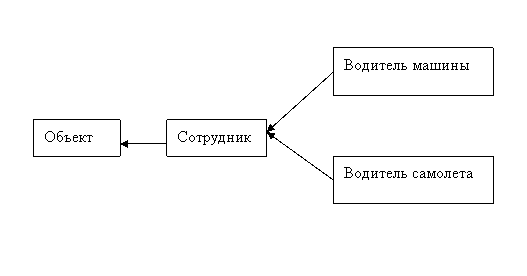
Рисунок 1. Дерево наследования
Разрешим нашему объекту в качестве своего типа иметь не один узел этого дерева, а любое поддерево этого дерева, содержащее корень. Этого достаточно, чтобы описать приведенный пример. Такой тип объекта будем называть «тип-множеством». Прежнее понятие типа (тип - узел) является частным случаем нового. Достаточно по узлу построить путь, идущий в этот узел из корня и принять за тип-множество узлы этого пути. Если разрешены ярлыки, то таких путей несколько. В этом случае объединим в тип-множество все узлы всех этих путей.
Тип-центр
(М) Если тип-множество не является цепью (линией), то какой иконой представить этот объект в интерфейсе? Для решения этой проблемы выделим в тип-множестве один узел и объявим его «тип-центром». Именно он задаст икону при отображении объекта. Кроме того, видимые элементы данных и видимые функции по умолчанию тоже определяются по «тип-центру»
Еще операции
К четырем основным операциям, описанным выше (создать узел, изменить узел, удалить узел, передвинуть узел) теперь можно добавить еще операции
- Изменить тип узла (для объектов только)
- Создать ярлык узла данного узла и передвинуть его по адресу
На ярлыке возможны только две операции
- Удалить ярлык
- Создать ярлык по ярлыку и передвинуть его по адресу
Считается, что при создании ярлыка по ярлыку второй ярлык указывает на тот же узел, что и первый и что для системы они одинаковы (хотя их порядок может иметь значение)
Права пользователя
Зона компетенции
Если объект входит в зону ответственности данного пользователя, то у пользователя есть право делать с этим объектом «что угодно», например, изменить или удалить его. В частности, пользователь может изменить тип объекта. Однако право «изменить тип объекта» должно быть ограничено сообразно «компетенции» данного пользователя.
Приведем пример.
Таблица 1. Компетенции и документы.
|
|
Компетенция |
Документ |
|
1 |
Менеджер |
Распоряжение |
|
2 |
Конструктор |
Чертеж |
|
3 |
Технолог |
Технологические данные |
|
4 |
Бухгалтер |
Ведомость |
Если у менеджера есть объект «распоряжение», то обычно не стоит давать ему право превращать это распоряжение в «конструкторский чертеж» или «бухгалтерскую ведомость». Однако иногда такое возможно. Как описать эту ситуацию в терминах нашей модели?
Назовем «зона компетенции» данного пользователя объединение всех тип-множеств всех объектов в его зоне ответственности. При изменении типа любого объекта эта зона компетенции не должна расширяться. Увеличить компетенцию сотрудника может только его начальник – но не он сам.
(Р) Поскольку зона ответственности пользователя может быть очень велика, то в текущей реализации зона компетенции вычисляется не по всем объектам зоны компетенции, а только по тем, которые видны в интерфейсе в данный момент.
Как начальник может увеличить подчиненному зону компетенции?
Во-первых, зона ответственности начальника не меньше чем зона ответственности подчиненного. Соответственно область компетенции начальника не меньше чем область компетенции подчиненного. Начальнику достаточно «передвинуть» один объект из своей зоны ответственности в зону ответственности подчиненного, чтобы увеличить зону компетенции подчиненного.
Зона компетенции администратора пространства включает в себя все типы, известные системе (все дерево наследования).
Создание объектов
(М) Создание объекта под определенным узлом ограничено типом этого узла.
Логично определить, чтобы в «папке для чертежей» создавались только «чертежи», а в «папке для распоряжений» - только «распоряжения».
(Р) Некоторые типы (в данной реализации это тип «папка») можно создавать везде.
(М) Остальные типы подчиняются следующему правилу:
- Есть «дерево вложенности типов»
- Если в этом дереве тип А лежит является прямым потомком типа Б, то в дереве объектов под объектом типа Б разрешается создавать объекты типа А
- Все типы (кроме абстрактных) входят в дерево вложенности один раз. Абстрактные типы в дерево вложенности не входят.
(Р) Корень дерева вложенности – тип OBJECT.
В дереве вложенности разрешены ярлыки, что превращает его в ациклический граф.
Групповое создание объектов
(Р) Иногда требуется создать одной командой несколько объектов. В текущей реализации есть следующие способы создания объектов под данным объектом (номера соответствуют интерфейсу).
Обратите внимание на то, что в описании способов создания используется новый термин «адрес». Адрес указывает на объект. Как он строится и как анализируется, мы укажем ниже. Кроме того, используются термины «имя узла» и «код узла». Имеются в виду узлы дерева объектов и узлы дерева типов (в дереве наследования и в дереве вложенности одни и те же узлы). «Код» и «Имя» мы определим ниже. Кроме того, появляется термин «скрипт». Он тоже будет описан ниже. Кроме того, появился термин «запрос». Он тоже будет описан ниже. Параметры запроса тоже будут описаны ниже
Способы создания объектов
- Один объект (сообразно дереву вложенности)
- Несколько объектов. Тип задан по дереву вложенности. По указанным адресам считываются имена и присваиваются новым объектам по списку. Соответственно создается столько объектов, сколько перечислено адресов.
- Объекты
по списку. Как в предыдущем пункте с тем отличием, что задается только
один «опорный адрес», а список «образцов» берется как список детей лежащих
в дереве объектов непосредственно под этим «опорным объектом»
- Дерево по образцу. Считается, что в дереве объектов
уже есть поддерево-образец. Указан адрес корня образца.
Следующие способы создания доступны только администратору пространства. В этих способах тип вычисляется. Тип, заданный в форме, игнорируется. - Объект по типу. Задан номер типа.
- Дерево по типу, коды. Задан номер типа. В качестве кода новому объекту присваивается код его типа
- То же, что в предыдущем варианте, но в качестве кода новому объекту присваивается его номер.
- Объекты создаются согласно скрипту, прочитанному из файла
- Под данный объект добавляются ярлыки объектов найденных по запросу. Объект-запрос задается адресом. Параметры запроса берутся из имени объекта в котором происходит создание
Код и имя
У каждого узла (объекта, типа) есть код и имя.
Имя может быть пустым, код пустым быть не может.
Код типа уникален в дереве типов
Код объекта уникален среди детей одного объекта.
(Р) Код корня дерева объектов – маленькая латинская буква «о»
(Р) Код корня дерева типов – «object»
У ярлыков своего кода нет (точнее, он есть, но никогда не демонстрируется), код берется из объекта. Теневым полем (смотри ниже) код быть не может. Под одним родителем допустимы несколько ярлыков одного объекта, уникальность кода при этом не проверяется.
(Р) На код типа накладываются ограничения достаточно строгие, чтобы он мог служить именем таблицы в используемой СУБД. Мы используем здесь только маленькие латинские буквы, цифры и знак подчеркивания, первый знак – буква
Номер, код и путь
Из сказанного ясно, что имени может не быть, а код есть всегда, и у типа, и у объекта. Спрашивается: можно ли по коду найти узел?
Для типа: да, можно, код типа уникален в системе
Для объекта: нет нельзя, код типа уникален только у детей одного родителя.
Но это последнее условие позволяет идентифицировать объект по пути:
(Р) синтаксис пути похож на синтаксис URL, например, так:
o/123/abc/1q2w3
Здесь используются коды объектов, лежащих на пути от корня к объекту
Уникальный номер есть у каждого объекта и каждого типа. Номер можно использовать внутри системы, но в разных системах номера одних и тех же типов (объектов), совпадать не обязаны. Поэтому в скриптах (смотри ниже) для идентификации объекта или типа номера не используются, а только коды и пути
Адреса
При выполнении некоторых операций (например, «сдвинуть»), приходится указывать узел. Как это сделать? В общем случае такое указание называется адресом.
(Р) Поскольку иногда пользователю (администратору пространства) приходится работать сразу с несколькими деревьями (объектов, наследования, вложенности), то по адресу должен не только восстанавливаться узел, но и дерево.
(Р) В системе приняты следующие соглашения
Если адрес – целое число, то это - дерево объектов, и это число – номер.
Если адрес начинается с буквы, то сразу за ней должно идти целое число
Разрешены следующие буквы:
A, a – для дерева объектов
H, h – для дерева наследования
T, t – для дерева вложенности
Целое число означает:
После А – номер объекта
После а – номер узла в видимом интерфейсе (с номером объекта не совпадает, виден в браузере). Позволяет различать объекты и псевдообъекты.
После H, h, T, t – номер типа
(Р) При работе с основным интерфейсом (слева дерево, справа - узел) маленькая буква требует, чтобы узел был виден в дереве, большая – не требует.
В дереве типов (в отличие от дерева объектов) различать узлы и псевдоузлы не требуется. Почему? Поскольку в дереве объектов список операций над псевдоузлами существенно меньше, чем над узлами, а в дереве типов эти списки одинаковы.
Теневые поля
В некоторых задачах объект создается один раз, а ярлыки его используются многократно. При этом каждый такой ярлык должен нести некую информацию, привязанную к месту.
Пример: дерево сборки, в котором узлами являются детали и узлы, входящие в изделие.
Каждая деталь (узел, ДСЕ – деталесборочная единица) описана в системе только один раз. Включая ее в разные узлы и изделия мы должны указать кратность такого включения. Эта кратность есть поле привязанное к ярлыку, но не к объекту.
До сих пор у нас не было возможности хранить в ярлыке данные, неизвестные в объекте. Для того, чтобы такая возможность появилась в описании типа некоторые поля объявляются «теневыми».Это означает, что значение этого поля в ярлык не копируется из объекта, а в каждом ярлыке определяется независимо.
Другой пример: объект – человек, а его ярлыки обозначают его вхождение в различные группы. Тогда дата вступления в группу может быть теневым полем
Слепые узлы и ярлыки
Есть примеры, когда пользователю разрешено видеть объект и даже изменять его, но не разрешено видеть объекты, лежащие ниже его по дереву. (Администратор пространства всегда видит все.)
Пример: учитель видит ученика, но не видит его личные документы
Вариант: учителю дан ярлык на ученика.
Такие объекты или ярлыки, под которыми не видны существующие дети, называются «слепыми». Объявить или отменить «слепоту» может только администратор
Фантомные ярлыки
Есть случаи, когда ключ указывает на место объекта в иерархии, но сам объект создан вне этой иерархии. Можно объявить этот ключ «фантомным» и тогда при просмотре иерархии ярлык на этот объект будет изображен в нужном месте иерархии. При этом ярлык будет именно изображен, а не создан. Его нельзя удалить, но можно снять с ключа атрибут «фантомный», и он исчезнет. И его нельзя переместить, но можно в самом объекте изменить значение ключа и он переместится соответственно.
Пример: люди и отделы
Сильные функции
Некоторые функции на объекте могут изменять базу данных. Такие функции называются «сильными» (остальные – «слабыми»). При создании функций (см. ниже) «сильность» надо объявлять особым образом. В интерфейсе сильные функции появляются по специальному требованию. В публикации дерева (см. ниже) они не появляются
Запрос
Обязательные типы
(Р) Нам уже известны некоторые типы, присутствие которых в системе обязательно
Добавим к ним еще два
Таблица 2. Обязательные типы
|
ID |
Код |
Имя |
|
0 |
object |
Объект |
|
1 |
xuser |
Пользователь |
|
2 |
folder |
Папка |
|
3 |
qfolder |
Папка запросов |
|
4 |
query |
Запрос |
Папка запросов позволяет (по дереву вложенности) создавать запросы. Кроме того (функция) она умеет выполнять по одной команде все запросы в нее попавшие.
Выполнение запроса
(Р) В запросе есть специальное поле, которое содержит запрос на языке SQL совместимом с СУБД, на котором реализована система. Основная функция, выполнимая на этом типе, выполняет данный SQL-запрос на данной СУБД.
Для того, чтобы результаты запроса можно было оформить как таблицу или последовательность таблиц, в объекте есть еще один параметр – «уровень разрезания». Если этот параметр равен нулю, то все результаты составляют одну таблицу. Если этот параметр (целое число) равен Х>0, то первые Х полей результата выносятся в заголовок таблицы. При изменении хотя бы одного из этих полей старая таблица закрывается и открывается новая.
Параметры запроса
Есть случаи, когда хранимый запрос перед выполнением надо модифицировать. Иногда требуется модифицировать один фрагмент запроса, иногда – несколько. При этом выполнение такого запроса без модификации не должно приводить к непредсказуемым или аварийным ситуациям.
Проблема решается следующим образом.
Сначала анализируется строка параметров. Если в ней есть знак «=», то считается, что следует подставить несколько параметров, иначе – один.
Если следует подставить несколько параметров, то в теле запроса ищется знак @ и вместо него подставляется вся строка параметров как один элемент.
Если параметров несколько, то считается, что строка параметров состоит из нескольких фраз вида
Имя-переменной = значение-переменной
разделенных знаком «точка с запятой» (;)
На первом этапе система разбивает строку параметров на такие фразы.
На втором этапе для каждого параметра с именем Х ищется в теле запроса фрагмент вида
@X#
Этот фрагмент заменяется на значение переменной
Еще одно поле объекта хранит строку параметров, которая подставляется по умолчанию до подстановки строки параметров в момент выполнения.
Поддерево как значение
Если при разбиении строки параметров на фразы перед знаком точка с запятой (;) будет обнаружена вертикальная черта (|), то такое значение до подстановки обрабатывается специальным образом
- Считается, что это ID объекта
- В дереве объектов выделяется «корневой объект» с таким ID
- Перечисляются все объекты лежащие в «поддереве корневого объекта». Составляется строка ID этих объектов (включая корневой объект) через запятую
- Эта строка считается значением параметра для подстановки
Когда используется такая подстановка?
Например, если справочник категорий организован иерархически, то, используя в запросе
AND
id
IN (@)
можно ограничить поиск той частью справочника, которая лежит внутри данной категории
Запрос-ссылка
Этот тип (QUERYREF)
похож на запрос (QURY),
но вместо тела запроса имеет ключ, указывающий на другой запрос. Он не является
обязательным.
Публикации
(Р) Публикация (определение) это создание статического
сайта или страницы на основе динамического сайта или страницы соответственно. Динамические
данные видимы только в определенной сети (1) при работающем сервере (2) и при
соответствующей авторизации (3). Статические данные в этих условиях не
нуждаются, их можно тиражировать, смотреть на локальном компьютере и пр. В
системе существует несколько независимых способов публикации.
Отчет
Если при выполнении функции получен отчет, то его можно
опубликовать. На странице отчета есть линк,
вызывающий эту операцию. Результатом будет новый линк
к статической странице с тем же содержанием. Этот линк
уже не требует авторизации, хотя еще требует сети и работающего сервера.
Дерево
Любое поддерево объектов может быть опубликовано. При этом
создается папка в которой индекс содержит все вершины
поддерева с отступом сообразно вложенности. Ниже каждого объекта перечислены все
его функции (кроме функций унаследованных от «object»). Узлы этого нового дерева
линкованы на созданные тут же статические файлы. Для объектов это элементы
данных (список пар «имя-значение»). Для функций это результат при пустой строке
параметров.
Word
Всякий объект можно опубликовать в виде файла WORD. Для этого надо сначала
заготовить шаблон. Шаблон должен быть в формате XML. В тех местах, где мы желаем
появления элементов данных из объекта надо вставить внутреннее имя поля. Вместо
него в момент публикации будет подставлено значение элемента.
Например, вместо
object::code
будет подставлено значение этого элемента в данном объекте
Пути
(Р) Все публикации происходят в предопределенных папках
сервера.
Есть папка PUB.
Публикации отчетов попадают в эту папку. Внутри PUB папка WT содержит
шаблоны WORD, а папка WD –
результаты публикации. Шаблон определяется по номеру типа (например, 12.xml, если номер типа = 12). Результат
называется по номеру объекта, например 1234.xml, если номер объекта = 1234
Путь к результирующей папке при публикации дерева задается. Однако
он должен вести к локальной папки сервера, указанного
при работе с машины-сервера.
Что такое FTS
Предисловие
Что такое FTS
Для кого предназначена эта книга
Об авторе
Терминология
Общие соображения
Продукт одного программиста
Уровни определенности
Постановка задачи
Выбор пути
Модель данных
Качество
Качество и ответственность
Дерево объектов
Данные, функции, операции
Тип объекта
Элементы данных
Номер объекта
Ключи
Основные операции
Реальные ситуации
Область видимости
Ярлыки
Псевдоузлы
Переменный тип объекта
Наследование
Номер типа
Внешнее и внутреннее имя типа
Абстрактный тип
Множественное наследование
Ярлыки в дереве наследования
Тип-множество
Тип-центр
Еще операции
Права пользователя
Зона компетенции
Создание объектов
Групповое создание объектов
Способы создания объектов
Код и имя
Номер, код и путь
Адреса
Теневые поля
Слепые узлы и ярлыки
Фантомные ярлыки
Сильные функции
Запрос
Обязательные типы
Выполнение запроса
Параметры запроса
Поддерево как значение
Запрос-ссылка
Публикации
Отчет
Дерево
Word
Пути